
Introducción
Podríamos definir los Datasets como <<un conjunto de datos o información que es tratada como una unidad por parte de un sistema>>. Estos Datasets pueden contener imágenes, texto, vídeos, etc y son utilizados por las Inteligencias Artificiales para entrenar sus modelos, permitiendo que el modelo aprenda patrones y pueda luego realizar predicciones o clasificaciones en nuevos datos.
El origen de los datasets plantean muchas dudas en relación con el cumplimiento y respecto de los derecho de autor, dado que los modelos de la mayoría de plataformas, como por ejemplo es el caso de OpenAI, informan que sus modelos se desarrollan utilizando principalmente tres fuentes: (1) información pública disponible en internet, (2) licencias de terceros y (3) sus propios usuarios.1

El Reglamento de IA
Siendo así, parece bastante probable que dentro del conjunto de datos que utilizan de internet existan algunos que puedan estar vulnerando los derechos de autor. Por esta razón el Reglamento de IA introduce ciertas obligaciones a las plataformas de IA (a los que llama proveedores) para que sean más transparentes. El desarrollo de estas obligaciones de transparencia se aplicarán a los sistemas de IA de “Limited Risk”(que son la mayoría de plataformas que utilizan los usuarios, como es el caso de ChatGPT). Estas obligaciones se mencionan en el artículo 52 pero en lo que respecta a las obligaciones de transparencia de los datasets y el impacto que esto tiene a los derechos de autor se desarrollan en los Considerandos (del 105 al 107).
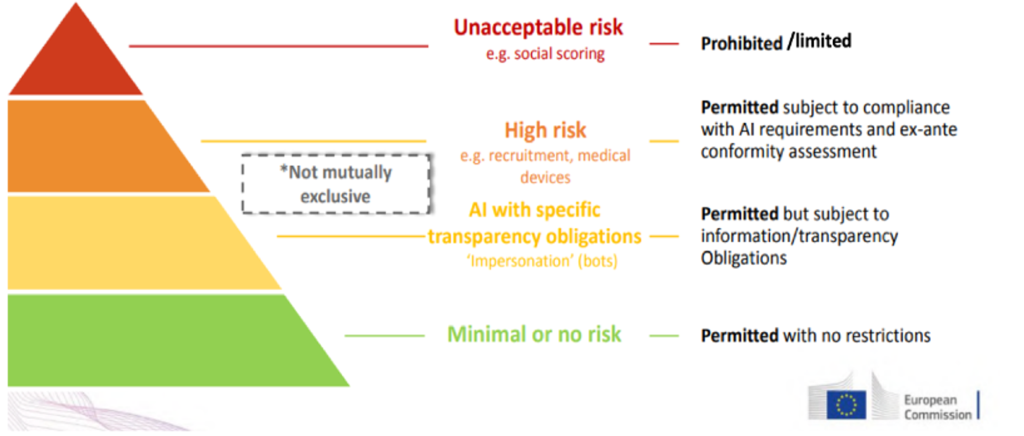
Es el Considerando 105 quien afirma que <<el desarrollo y entrenamiento de estos modelos requiere el acceso a grandes cantidades de texto, imágenes, vídeos y otros datos […] que pueden estar protegidos por derechos de autor y derechos afines>>. Desde el 105 hasta el 107 se hace referencia a los dataset y al proceso de entrenamiento (en ingles conocido como data mining), indicando que los proveedores de los modelos de IA deben garantizar que sus modelos respetan la normativa referente a los derechos de autor y derechos afines, y en particular en lo referente a identificar y cumplir la reserva de derechos expresada por los titulares de derechos (lo que se conoce como Derecho de Opt Out).
Luego el Considerando 107, desarrolla estas obligaciones de transparencia impuestas a los proveedores de modelos de IA bajo indicación que cuando se utilicen datos de entrenamiento se deberá poner a <<disposición del público un resumen suficientemente detallado del contenido utilizado para el entrenamiento del modelo de IA […] por ejemplo, enumerando las principales colecciones o conjuntos de datos que se utilizaron para entrenar el modelo, como grandes bases de datos privados o públicos o archivos de datos, y proporcionando una explicación narrativa sobre otras fuentes de datos utilizadas>>. Esto tiene todo el sentido dado que difícilmente los autores pueden saber o revisar si sus obras han sido utilizadas en los dataset sólo por el resultado de los outputs cuando el proceso de entrenamiento de los modelos justamente lo que hace es desenfocar o añadir ruido a las mismas (ver anterior artículo sobre IA Generativa para entender el funcionamiento).
Ni OpenAI ni Midjourney, para poner un ejemplo, son transparentes en explicar el origen de su datasete incluso alegan que es imposible entrenar a los modelos sin infringir material protegido por derechos de autor. De hecho, ya existen varios casos judiciales abiertos en otros países como el famoso caso del New York Times vs OpenAI en los que se está demostrando que los modelos de IA no sólo es que se hayan entrenado con datos no autorizados, sino que además extrae contenidos prácticamente idénticos en cuanto a forma o estilo de redactado (BARRABI, THOMAS 2023)2
La postura que están tomando las plataformas de IAG para defenderse al ser incapaces de conocer el alcance de sus dataset es justificar la vulneración de los derechos de autor en base a la doctrina del <<Fair Use>> (uso legítimo) que estableció un precedente importante en relación con la digitalización de libros y la creación de una biblioteca digital en línea en los Estados Unidos en la Sentencia de Authors Guild, Inc. V. Google, Inc., 804 F.3d 202 (2d Cir. 2015) según WES DAVIS (2023).
De la misma manera que dentro de la propiedad intelectual el autor puede ceder alguno de los derechos de explotación asociados al derecho de autor o puede estipular el carácter de la obra (como por ejemplo sucede en los Creative Commons) podría resultar útil utilizar una fórmula similar donde el autor pudiera etiquetar que en su caso o en el caso de una obra en particular, no quiere que sea utilizada (o explotada) en ese sentido; es decir en que sea utilizado para entrenar un modelo de IA (lo que en efecto seria ejercer ese derecho de opt out).
Mientras tanto hay plataformas como OpenAI que utilizan prompts secretos para prevenir que los usuarios puedan dar instrucciones que generen contenido potencialmente protegido por los derechos de autor. Se consideran <<secretos>> porque no es una instrucción que pueda ver el usuario, sino que ha sido revelado por el modelo a través de diferentes técnicas de expertos para revelar la fuente del código (MEDIUM, 2024)3
Estos ejemplos nos muestra que las plataformas de IA son conscientes que su dataset infringe con el derecho de autor y utilizan medidas que no son transparentes como busca el AIA.

- CLABURN, THOMAS. <<OpenAI: “Imposible to train today’s leading AI models without using copyrighted materials”>>. The Register. 8 enero 2024. Disponible en: https://www.theregister.com/2024/01/08/midjourney_openai_copyright/↩︎ ↩︎
- BARRABI, THOMAS. <<New York Times sues OpenAI, Microsoft for seeking to “free-ride” on its article to train chatbots>>. New York Post. 27 de diciembre de 2023. Disponible en: https://nypost.com/2023/12/27/business/new-york-times-sues-openai-microsoft-for-using-articles-to-train-chatgpt-other-ai-models/↩︎ ↩︎
- <<The Secret Prompt of ChatGPT4>>. MEDIUM, 14 de febrero 2024, 14 de junio 2024, 16:49h. Disponible en: https://medium.com/@jhoansfuentes1999/the-secret-prompt-of-chatgpt-4-924426c7e0e0 ↩︎ ↩︎